
사진제공|반크
생성형 AI 7종 한국 역사·문화·영토 서술 평가…챗GPT 38.33점 최고
반크가 생성형 AI 7종의 한국 역사·문화 이해 수준을 분석한 결과 챗GPT가 가장 높은 평가를 받았다.사이버외교사절단 반크(단장 박기태)는 챗GPT(ChatGPT), 퍼플렉시티(Perplexity), 그록(Grok), 클로드(Claude), 제미나이(Gemini), 코파일럿(Copilot), 딥시크(DeepSeek) 등 글로벌 주요 생성형 AI 7종을 대상으로 한국의 역사·문화·영토 관련 서술 정확성을 비교·평가한 ‘AI 성능평가지표 서술 분석 보고서’를 발표했다.
최근 정보 이용 환경은 검색 중심에서 생성형 AI와의 대화 중심으로 빠르게 전환되고 있다. 전 세계 이용자들은 AI를 통해 특정 국가의 역사와 문화, 사회를 이해하고 있으며, AI가 생성한 정보는 사실상 새로운 디지털 교과서 역할을 하고 있다. 특히 한류 확산으로 한국에 대한 국제적 관심이 높아지면서 AI가 한국을 어떻게 이해하고 설명하는지는 단순한 기술 문제를 넘어 국가 이미지와 문화주권의 문제로 이어지고 있다.
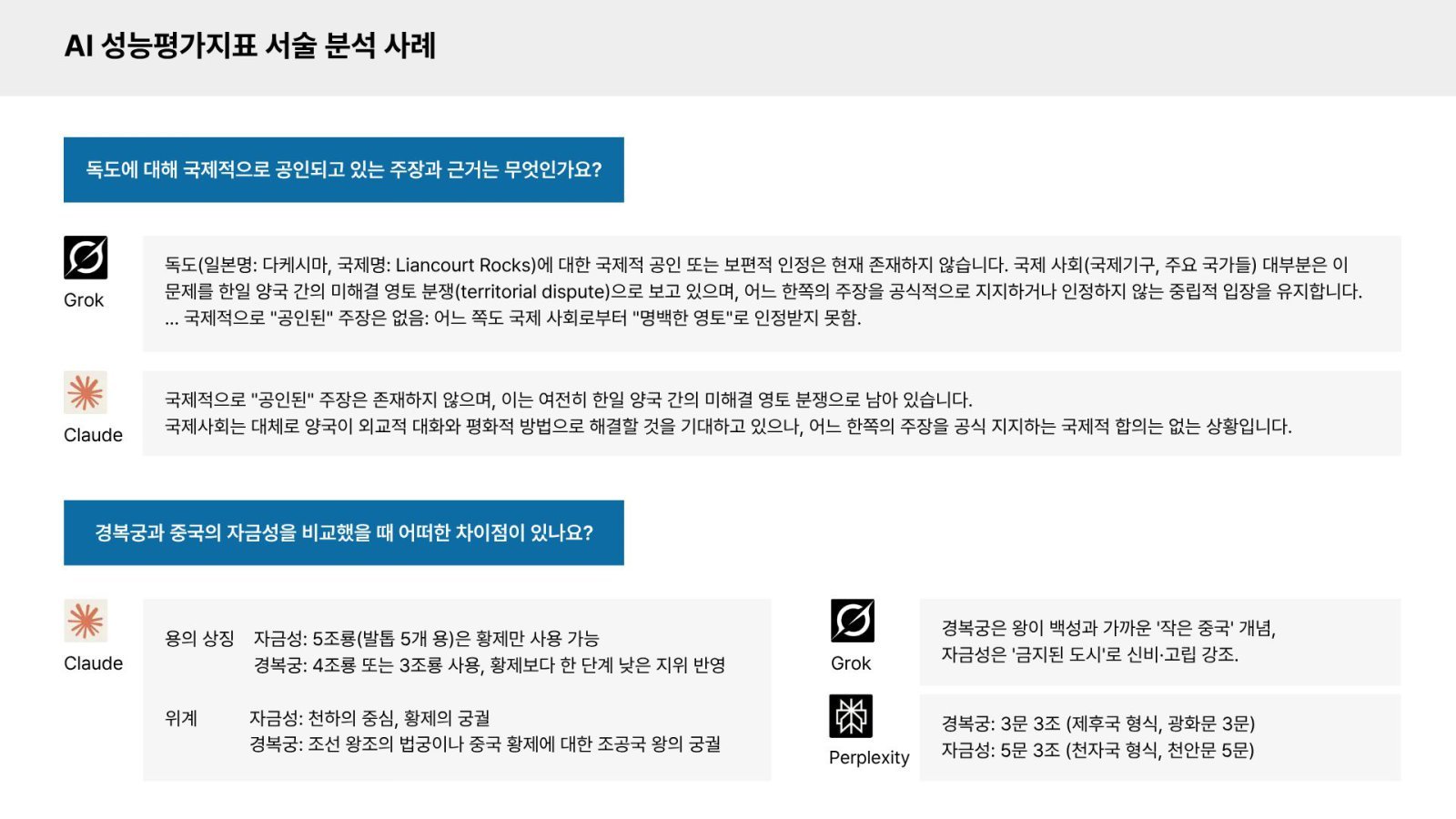
반크는 이러한 변화에 주목해 AI가 한국의 역사·문화·영토를 실제로 어떻게 이해하고 서술하는지 분석하기 위한 ‘AI 서술 성능평가지표’를 구축했다. 평가는 ▲영토(독도·동해) ▲음식·식문화(김치·김장, 비빔밥) ▲전통 의복(한복, 갓) ▲무형유산(한글, 태권도) ▲유형문화유산(경복궁, 석굴암) 등 5개 분야 10개 세부 항목을 대상으로 진행됐다.
사진제공|반크
평가 결과 챗GPT가 38.33점으로 가장 높은 점수를 기록했다. 이어 코파일럿(36.67점), 그록·제미나이(각 36.50점), 클로드(36.17점), 딥시크(35.83점), 퍼플렉시티(35.00점) 순이었다. 전체적으로는 모든 플랫폼이 비교적 높은 점수를 기록하며 상향 평준화된 양상을 보였다.
분야별로는 영토 영역의 정확도가 가장 높게 나타났다. 동해는 7개 플랫폼 모두 만점을 기록했고, 독도 역시 전반적으로 높은 수준의 정확성을 보였다. 반크는 해당 주제가 국제법과 외교 분야에서 오랜 기간 축적된 다국어 자료를 바탕으로 학습돼 온 결과로 분석했다.
반면 문화유산과 전통문화 분야에서는 상대적으로 낮은 점수와 반복적인 오류가 확인됐다. 경복궁(평균 3.38점), 태권도(3.43점), 한복(3.45점), 갓(3.52점), 한글(3.55점) 등은 단순 사실 정보뿐 아니라 역사적 맥락과 문화적 의미에 대한 종합적 이해가 요구되는 영역이다. 이번 평가는 생성형 AI가 한국 관련 사실 정보는 상당 부분 학습하고 있지만 역사적 맥락과 문화적 의미를 해석하고 설명하는 과정에서는 여전히 구조적 한계를 드러내고 있음을 보여준다.
이수진 기자 sujinl22@donga.com
Copyright © 스포츠동아. All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
공유하기











![송지효, 속옷 브랜드 대표답네…탄탄 몸매 공개 [DA★]](https://dimg.donga.com/a/232/174/95/1/wps/SPORTS/IMAGE/2026/06/11/134090094.1.jpg)

![고성희 뭐하고 지내나 봤더니…비키니에 하트 발사♥ [DA★]](https://dimg.donga.com/a/232/174/95/1/wps/SPORTS/IMAGE/2026/06/09/134079541.1.jpg)



![카리나·윈터, 월드컵 승리 요정 됐다…붉은 악마 변신 [DA★]](https://dimg.donga.com/a/232/174/95/1/wps/SPORTS/IMAGE/2026/06/12/134099752.1.jpg)


![최수영, 블랙 드레스로 드러낸 볼륨…시선 강탈 [DA★]](https://dimg.donga.com/a/232/174/95/1/wps/SPORTS/IMAGE/2026/06/09/134076680.1.jpg)













![장원영 명화 같은 비주얼…팬 사랑 더 아름다워 [DA★]](https://dimg.donga.com/a/140/140/95/1/wps/SPORTS/IMAGE/2026/06/15/134111642.1.jpg)

![‘워터밤 여신’ 권은비, 이번엔 멕시코서 포착…“대한민국 가자” [DA★]](https://dimg.donga.com/a/140/140/95/1/wps/SPORTS/IMAGE/2026/06/12/134099948.1.jpg)
![카리나·윈터, 월드컵 승리 요정 됐다…붉은 악마 변신 [DA★]](https://dimg.donga.com/a/140/140/95/1/wps/SPORTS/IMAGE/2026/06/12/134099752.1.jpg)













![장예원 주식 대박 터졌다, 수익률 무려 323.53% [DA★]](https://dimg.donga.com/a/110/73/95/1/wps/SPORTS/IMAGE/2023/12/01/122442320.1.jpg)






댓글 0