정보기술(IT) 기업들이 글로벌 테크 기업의 새 트렌드로 자리 잡은 ‘초거대 인공지능(AI)’ 개발에 속속 나서고 있다. 초거대 AI는 종합적이고 자율적으로 사고, 학습, 판단, 행동하는 인간의 뇌 구조를 닮은 AI다. 프로기사 이세돌 9단과 세기의 바둑을 둔 ‘알파고’와 달리 특정 영역이 아닌 여러 분야에서 학습이 가능한 것이 특징이다. 다양한 서비스와 산업에 적용 가능한 차세대 AI로 주목받으면서, 국내 IT기업들도 슈퍼컴퓨팅 등 인프라 구축과 함께 언어모델 개발 등을 추진하고 있다.
인간 뇌를 닮은 AI
초거대 AI의 대표적 예가 바로 미국 AI연구소 오픈AI가 개발한 영어 기반 AI 언어 모델 ‘GPT-3’다. 인간처럼 자연스러운 대화가 가능하고, 에세이나 소설까지 창작할 수 있다.
GPT-3는 1750억 개의 파라미터(매개변수)를 가지고 있다. 파라미터는 서로 다른 함수에 공통적으로 영향을 미치는 변수로, 인간 뇌에서 뉴런을 연결해 정보를 학습하고 기억하는 역할을 하는 시냅스와 유사하다. 보통 파라미터 규모가 클수록 AI의 지능은 높아지는데, GPT-3는 이전 버전인 GPT-2보다 100배 이상 크다.
초거대 AI는 다양한 산업군에서 활용이 가능하다. 감성대화와 검색, 고객센터 등 관련 서비스에 적용하는 것은 물론 기업 내 업무 효율을 높이고, 제품 개발 프로세스를 단축할 수도 있다. 이 때문에 구글과 마이크로소프트(MS), 페이스북 등 글로벌 테크 기업들 모두 기술 확보에 공을 들이고 있다. 최근에는 구글이 인간처럼 자연스러운 대화가 가능한 ‘람다’를 공개하기도 했다.
네이버, 언어모델 검색에 적용
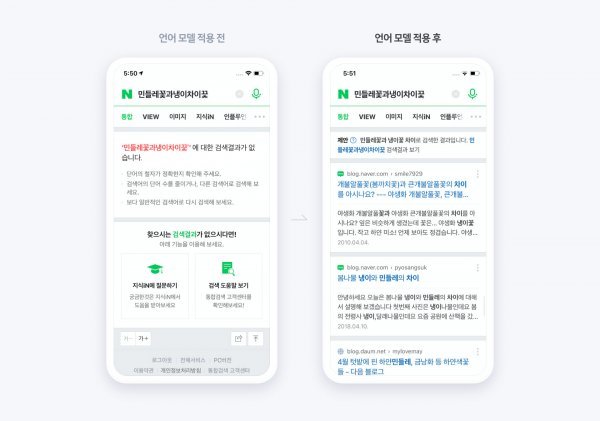
활용 분야가 넓은 만큼 한국 기업들도 속속 기술 선점 경쟁에 뛰어들고 있다. 가장 발 빠른 것은 네이버다. 이 회사는 25일 온라인으로 열리는 ‘네이버 AI 나우’에서 초거대 AI 모델을 처음 공개한다. 지난해 10월 초거대 언어모델 구축을 위해 슈퍼컴퓨터를 도입한 네이버는 최근 국내 최초로 개발한 한국어 기반 초거대 AI 언어 모델을 검색 서비스에 적용했다. 사용자가 잘못 검색어를 입력해도 관련 검색 결과를 찾아준다. 예를 들어 ‘민들레꽃과냉이차이’이라 검색하더라도 ‘민들레꽃과 냉이꽃 차이’로 자동 변환해 결과를 보여준다. 네이버는 25일 이런 초거대 AI에 대해 설명하고, 다양한 협력 계획도 발표할 예정이다.
대기업들도 초거대 AI에 관심을 보이고 있다. LG그룹은 AI 전담조직 LG AI연구원을 통해 향후 3년 동안 1억 달러(약 1130억 원) 이상을 투자하기로 했다. 초거대 AI 개발을 위해 1초에 9경5700조 번의 연산 처리가 가능한 글로벌 톱3 수준의 AI 컴퓨팅 인프라를 구축할 계획이다. 하반기에는 GPT-3보다 3배 많은 6000억 개 파라미터를 갖춘 초거대 AI를 공개한다. 언어 뿐 아니라 이미지와 영상을 이해하고, 데이터 추론까지 가능할 것이란 게 LG 측 설명이다. LG는 내년 상반기에 조 단위 파라미터의 초거대 AI도 개발할 예정이며 글로벌 제조기업 중 이 같은 규모의 개발은 첫 사례가 될 것으로 보인다.
KT-카이스트 등 산학협력
초거대 AI 개발을 위해선 대용량 연산이 가능한 컴퓨팅 인프라와 함께 대규모 데이터, 연구 역량 등이 필요하다. 때문에 관련 기업들과 학계 등의 협력 사례도 속속 나오고 있다.
KT는 카이스트와 ‘AI 및 소프트웨어(SW)공동 연구소 설립을 위한 업무협약’을 맺었다고 23일 밝혔다. 대덕2연구센터에 연구소를 설립하고 연내 공식 출범할 계획이다. 연구소는 글로벌 시장을 주도할 차세대 AI 모델도 연구한다. GPT-3 이후 AI 모델을 공동 개발하는 등 ‘포스트 AI 시대’를 이끌어 간다는 목표다.
네이버는 서울대학교와 손잡았다. 초거대 AI 분야 공동 연구를 위한 연구센터를 설립할 계획이다. AI 연구원 100여 명이 참여하고, 3년 동안 연구비와 인프라 지원비 등을 포함해 수백 억 원 규모의 투자가 진행된다. 언어 뿐 아니라 이미지, 음성을 동시에 이해하는 초거대 AI를 개발해 글로벌 AI 기술을 선도하는 것이 목표다. 네이버는 슈퍼컴퓨팅 인프라와 데이터를 활용할 수 있도록 공유한다.
SK텔레콤은 카카오, 국립국어원과 손을 잡았다. 카카오와는 AI 기술을 개발하기 위해 인프라, 데이터, 언어모델 등 전 영역에서 협력한다. 올해부터 집중적으로 투자, 개발을 진행할 예정이다. 국립국어원과는 GPT-3와 유사한 성능을 발휘하는 한국어 범용 언어 모델(GLM)을 개발하기로 했다. SK텔레콤의 GLM은 1500억 개의 파라미터를 가진 모델로 개발 예정이다.
김명근 기자 dionys@donga.com
Copyright © 스포츠동아. All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
공유하기





















![신지원(조현), 힙업 들이밀며 자랑…레깅스 터지기 일보직전 [DA★]](https://dimg.donga.com/a/232/174/95/1/wps/SPORTS/IMAGE/2025/12/30/133063865.1.jpg)
![있지 채령, 허리 라인 이렇게 예뻤어? 크롭룩으로 시선 강탈 [DA★]](https://dimg.donga.com/a/232/174/95/1/wps/SPORTS/IMAGE/2025/12/30/133063831.3.jpg)






![“깜짝이야” 효민, 상의 벗은 줄…착시 의상에 시선 집중 [DA★]](https://dimg.donga.com/a/72/72/95/1/wps/SPORTS/IMAGE/2025/12/30/133061528.3.jpg)
![신지원(조현), 힙업 들이밀며 자랑…레깅스 터지기 일보직전 [DA★]](https://dimg.donga.com/a/72/72/95/1/wps/SPORTS/IMAGE/2025/12/30/133063865.1.jpg)






























![김남주 초호화 대저택 민낯 “쥐·바퀴벌레와 함께 살아” [종합]](https://dimg.donga.com/a/110/73/95/1/wps/SPORTS/IMAGE/2025/05/27/131690415.1.jpg)
![이정진 “사기 등 10억↑ 날려…건대 근처 전세 살아” (신랑수업)[TV종합]](https://dimg.donga.com/a/110/73/95/1/wps/SPORTS/IMAGE/2025/05/22/131661618.1.jpg)
댓글 0